O processo de adicionar e remover páginas no Google pode parecer simples, mas existem diversos pontos de atenção, principalmente quando se trata do Googlebot.
Por isso é importante que você saiba como o Google funciona antes de ler esse artigo.
O que é o Googlebot
O Googlebot é o rastreador da Web desenvolvido pelo Google para navegar e testar sites da internet. Ele também é conhecido como bot, crawler e spider, esse último nome se baseia na forma como o robô funciona, explicarei mais a frente.
Esse robô é apenas um dos principais rastreadores da internet, existem muitos outros que trafegam os sites diariamente em busca de páginas novas ou mudanças nas já existentes.
Outros crawlers conhecidos: Bingbot (Bing), Slurp Bot (Yahoo), DuckDuckBot (DuckDuckGo), Baiduspider (Baidu) e Yandex Bot (Yandex).
Como funciona
A maioria dos crawlers funciona da mesma maneira, eles buscam links em páginas já indexadas, testam a nova página, encontram links nela e partem para a próxima. Foi aí que surgiu o nome de Spider, pois ele vai construindo uma teia de página em página.
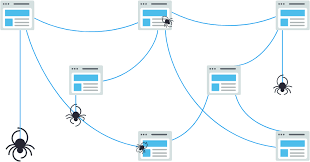
Fonte: Moz
As principais atividades do Googlebot são:
- Navegar pela internet em busca de novos links;
- Testar se eles links são indexáveis;
- Criar uma cópia da página para indexação;
- Validar o código e informações do site.
Após o trabalho do bot, o Google segue para os processos de indexação e classificação.
Googlebot Desktop x Mobile
Em dezembro de 2011, o Google lançou o Googlebot mobile, uma versão do robô que simula a navegação a partir de um celular. Isso foi necessário para melhorar a usabilidade de sites em dispositivos móveis, pois já era uma tendência naquele momento.
Essa tendência se manteve nos anos seguintes, o uso de celulares se popularizou cada vez mais e a navegação por Desktop deixou de ser o foco principal, foi então que em 2018 o Google anunciou que o Googlebot mobile se tornaria o crawler principal, essa atualização ficou conhecida como o Mobile First Index.
Como bloquear o acesso do Googlebot
Há quem pense que tudo que está na web é acessível indexável pelo Google, mas não é bem assim. Existem diversos sites e páginas que não estão presentes no buscador, isso sem falar em deep web.
Existem diversos motivos para bloquear a indexação ou rastreamento de uma página, pode ser um produto que ainda não foi lançado, uma página em construção, um site com problemas ou até mesmo um conteúdo que precisa de pagamento para ser acessado.
Confira alguns métodos para bloquear o robô do Google e aplicações:
Robots.txt
O robots.txt é um arquivo de texto salvo na raiz do site, ele possui diretrizes para todos os robôs da internet. É uma ferramenta muito útil para gerenciar conteúdos que não devem ser rastreados por robôs externos e que podem ser rastreados por robôs internos.
Aplicação: o robots.txt deve ser utilizado quando você possui um conteúdo que não deve ser rastreado pelo robô.
Como utilizar: crie o arquivo na raiz do site e inclua a seguinte informação:
User-agent: googlebot
Allow: /
Disallow: /pagina-para-bloquear/
Meta Tags
As meta tags são mais completas quando comparadas com o arquivo de texto. Você pode bloquear o rastreamento dos links contidos no conteúdo daquela página e ainda assim deixá-la disponível para indexação.
Aplicação: a meta tag noindex deve ser utilizada em páginas que não devem ser indexadas pelo buscador, mas que podem ser rastreadas. Páginas de agradecimento pelo contato, promoções rápidas e outros conteúdos temporários devem utilizar essa diretiva.
Como utilizar: para impedir todos os robôs, inclua o nome “robots” ou inclua “googlebot” para impedir apenas o Google de indexar a página:
<meta name=”robots” content=”noindex”>
ou
<meta name=”googlebot” content=”noindex”>
Outras ações
Existem outros tipos de controle que podem ser feitos com o robots.txt e com as meta tags, um desses é o bloqueio de uso do texto nos snippets de pesquisa, também conhecidos como posição zero.
Para bloquear o uso de textos do seu site na posição zero, adicione a tag <meta name=”robots” content=”nosnippet” /> no cabeçalho da página.
Eu não indico essa ação, pois snippet costuma gerar muito tráfego, mas é uma alternativa interessante para conteúdos delicados.
Como otimizar seu site para facilitar o trabalho do Googlebot
O Googlebot trabalha muito! Existem cerca de 2 bilhões de sites no mundo, todos eles são rastreados praticamente todos os dias, por isso o tempo de execução do robô dentro dos sites é limitado.
Existe uma série de ações que você pode realizar para garantir que o robô encontrará suas páginas:
- Tenha um Sitemap.xml com todas as páginas do site;
- Utilize o Google Search Console e envie seus dados por lá;
- Não utilize links nofollow, mesmo que o Google tenha alterado a forma de tratá-los;
- Crie links internos entre seus conteúdos;
- Evite erros 4XX e 5XX no site, isso atrapalha o trabalho do robô e pode até mesmo consumir o tempo de rastreamento do seu site com páginas que não existem.
O descaso com essas informações pode deixar seu site fora do Google.
Como testar se o Googlebot consegue rastrear seu site
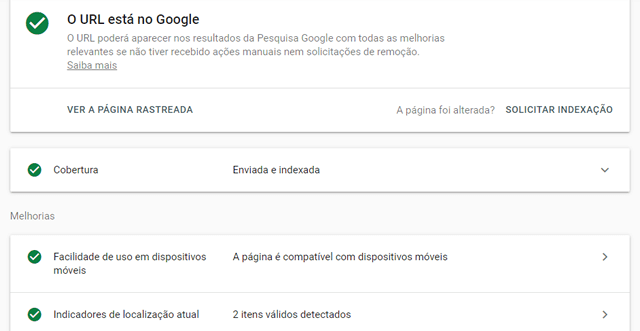
A forma mais simples de saber se o Google está conseguindo acessar o site é por meio do Search Console. Acesse a ferramenta, digite ou cole uma URL na caixa de busca na parte superior e dê enter.
Aguarde a pesquisa no índice do Google e confira os resultados. Todos os indicadores devem estar verdes, caso contrário, leia com atenção os possíveis problemas e atue na correção.
Esse artigo te ajudou a entender melhor o Googlebot? Compartilhe nas redes sociais e conte o que aprendeu!